이 글은 파이토치로 배우는 자연어처리(O'REILLY, 한빛미디어)를 공부한 내용을 바탕으로 작성하였습니다.
샘플(텍스트)의 인코딩
one-hot vector 만들기
from sklearn.feature_extraction.text import CountVectorizer
corpus = ['Time flies like an arrow.',
'Fruit flies like a banana.']
one_hot_vectorizer = CountVectorizer(binary=True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()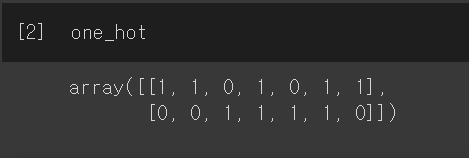
TF-IDF
- TF (Term Frequency) : 특정 단어가 특정 문서에서 등장한 횟수
- 'Time flies like an arrow.'에서 flies의 등장 횟수 = 1 = TF
- 높을 수록 중요도 ↑
- IDF (Inverse-Document-Frequency) : 특정 단어가 등장한 문서의 수에 반비례
- 특정 단어가 포함된 문서의 수 Nw 가 작을 수록 중요도 ↑
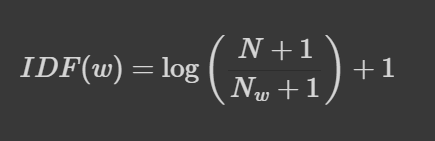
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer()
tfidf = tfidf_vectorizer.fit_transform(corpus).toarray()
Pytorch Tensor 다루기
# Tensor 랜덤 초기화
import torch
torch.rand(2,3) # 2행 3열의 텐서 생성, 0 ~ 1 사이 균등분포 원소
torch.randn(2,3) # 평균 0, 표준편차 1인 표준정규분포 원소# 0으로 이루어진 텐서
x = torch.zeros(2, 3)
# 1로 이루어진 텐서
x = torch.ones(2, 3)
# 원소를 5로 채우기
x.fill_(5)
# numpy 에서 tensor로
torch.from_numpy(npy)
# Tensor 원소를 범위(range)로 만들기
x = torch.arange(6)
# Tensor shape을 재설정하기
x.view(2,3)# 원소별 덧셈
torch.add(x, x)
x + x
# 전치
torch.transpose(x, 0, 1)
# tensor 인덱싱
indices = torch.LongTensor([0, 2])
torch.index_select(x, dim=0, index=indices)
# 차원 추가
x.unsqueeze(dim=1) # dim 차원에 추가
# 차원 삭제
x.squeeze() # flatten 작업 등에 쓰임
# 텐서 행, 열 방향으로 연결하기
torch.cat([x, x], dim=0)
torch.cat([x, x], dim=1)
# 텐서를 쌓아 새로운 0번째 차원에 연결하기
torch.stack([x, x])그래디언트와 계산 그래프
# gradient 계산에 사용하는 부가정보 관리 하기
x = torch.tensor([[2.0, 3.0]], requires_grad=True)
z = 3 * x
# .backward() 호출 후 grad 값 출력 (역전파 후에 grad가 기록된다.)
loss = z.sum()
loss.backward()
print(x.grad)CUDA 설정하기
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 어떤 환경에서든 실행되도록 코드 짜기
x = torch.rand(3, 3).to(device)
'AI 인공지능' 카테고리의 다른 글
| yelp 리뷰 감성 분석 (3) (0) | 2023.03.30 |
|---|---|
| yelp 리뷰 감성 분류 (2) (0) | 2023.03.30 |
| yelp 리뷰 감성 분류 (1) (0) | 2023.03.30 |
| 파이토치 신경망 구성하기 (0) | 2023.03.24 |
| 자연어처리(NLP) 기본 용어 정리 (0) | 2023.03.21 |