
제로베이스 데이터 취업 스쿨 과정 학습 내용을 정리한 포스팅입니다.
📍 분석용 데이터 준비
데이터셋 : 서울시 구별 CCTV 수, 서울시 구별 인구수
import pandas as pd
cctv_df = pd.read_csv("/content/drive/MyDrive/zerobase/seoul/01. Seoul_CCTV.csv", encoding="utf-8")
cctv_df.head()
cctv_df.rename(columns={cctv_df.columns[0]: "구별"},inplace=True)- df.rename 이용하여 첫번째 컬럼명을 "구별"로 바꾼다.
pop_df = pd.read_excel(
"/content/drive/MyDrive/zerobase/seoul/01. Seoul_Population.xls", header=2, usecols="B, D, G, J, N"
)
pop_df.head()
pop_df.rename(
columns={
pop_df.columns[0] : "구별",
pop_df.columns[1] : "인구수",
pop_df.columns[2] : "한국인",
pop_df.columns[3] : "외국인",
pop_df.columns[4] : "고령자",
},
inplace=True
)- 인구수 데이터에도 컬럼명을 변경해준다.
data_result = pd.merge(cctv_df, pop_df, on="구별") # how="inner" 가 기본값
data_result.head()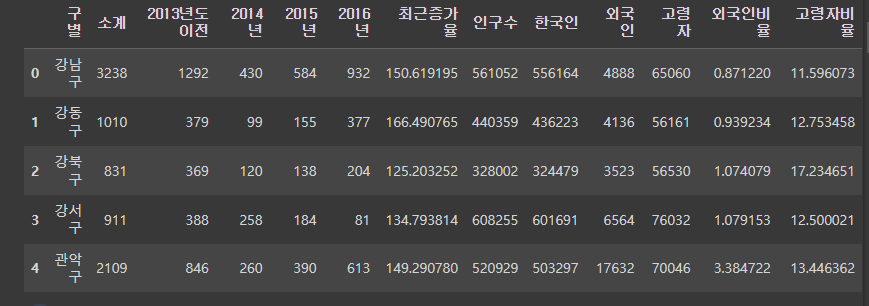
- pd.merge 로 "구별"을 기준으로 두 데이터셋을 합쳐준다.
📍 데이터 분석 시각화
def drawGraph():
data_result["소계"].sort_values().plot(
kind="barh",
grid=True,
title="가장 CCTV가 많은 구",
figsize=(10, 10)
)
drawGraph()
- df.sort_values() 로 내림차순 정렬하고, kind='barh'로 막대 수평그래프를 그려준다.
- CCTV 수 그래프로 시각화
import numpy as np
fp1 = np.polyfit(data_result["인구수"], data_result["소계"], 1) # y절편과, 기울기를 구해줌 (1 차식)
f1 = np.poly1d(fp1)- np.polyfit은 x, y 값을 넣으면 y절편과 기울기를 반환해준다.
- np.poly1d()를 하면 그 y절편과 기울기를 바탕으로 직선 함수를 반환한다.
data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])
df_sort_f = data_result.sort_values(by="오차", ascending=False)
df_sort_t = data_result.sort_values(by="오차", ascending=True)
df_sort_f.head()- f1()에 인구수 컬럼을 넣어 직선(경향)을 구해주고, 실제 소계값에서 이 f1 값을 뺀 "오차" 컬럼을 만든다.
- 전체 데이터셋을 오차를 기준으로 정렬한 데이터프레임을 선언해준다.
from matplotlib.colors import ListedColormap
color_step = ['#e74c3c', '#2ecc71', '#95aa56', '#2ecc71', '#3498db', '#3498db']
my_cmap = ListedColormap(color_step)- 그래프를 그릴 때, 색상을 설정하는 부분이다. 이 컬러맵을 my_cmap으로 저장해둔다.
def drawGraph():
plt.figure(figsize=(14, 10))
plt.scatter(data_result["인구수"], data_result["소계"],
c=data_result["오차"], s=50, cmap=my_cmap) # c= 색깔을 다르게 할 기준 설정, cmap = 색깔 종류
plt.plot(fx, f1(fx), ls="dashed", lw=3, color="g")
for n in range(5):
plt.text(
df_sort_f["인구수"][n] * 1.02,
df_sort_f["소계"][n] * 0.98,
df_sort_f.index[n],
fontsize=15,
)
plt.text(
df_sort_t["인구수"][n] * 1.02,
df_sort_t["소계"][n] * 0.98,
df_sort_t.index[n],
fontsize=15,
)
plt.xlabel("인구수")
plt.ylabel("CCTV")
plt.colorbar()
plt.grid()
plt.show()
drawGraph()
- plt.scatter로 x, y값의 산포도를 그린다.
- c=오차, cmap=my_cmap 으로 설정하면 산포도의 점들을 오차를 기준으로 색을 달리해 표현한다. (색을 6개 저장했으므로 6개 구역으로 표현)
- plt.text 를 이용해 오차 순위가 높은 5개 구, 낮은 5개 구에 구 이름을 적는다.
이로써 서울시의 구별 CCTV 수 경향성, 그리고
구 중에서 인구대비 CCTV 수가 많은 구와 적은 구를 파악할 수 있다.