자동차를 예로 들면, 자동차의 배터리가 차체와 일체형이 아닌 교체형일 때, 배터리(수정이 필요한 부분)만 교체할 수 있어서(결합도가 낮아서) 이상적인 프로그램을 만들 수 있다.
📍 클래스와 객체
기능들을 아우를 수 있는 클래스를 선언하고 그 안에 각 기능을 만든다.
객체 car1, car2는 클래스를 호출하여 만든 각각의 객체이다. car1과 car2 라는 객체로 작업함으로써 결합도를 낮춰 원본 클래스를 유지하면서 기능하게 할 수 있다.
생성자 __init__은 객체가 생성될 때 먼저 자동 호출된다. 속성을 초기화하는 기능
객체의 속성값(위의 예시에서는 color, length)은 객체에 따라 다르게 지정할 수 있으며, 지정 후에도 변경할수 있다.
car1.color = 'orange' # red를 orange로 변경
📍 얕은 복사, 깊은 복사
car1 = Car('red', 200)
위와 같이 객체를 생성한 경우 car1이라는 변수는 객체의 메모리 주소를 저장하고 이를 통해 객체를 참조한다.
얕은 복사
그런데, car3 = car1 과 같이 car3을 생성할 경우, 객체 자체가 복사되지 않고 참조하는 주소를 복사하게 된다.
즉, car1에서 속성을 변경할 경우 car3의 속성도 변경된다.(같은 주소를 바라보고 있기 때문에)
깊은 복사
깊은 복사를 할 경우, 참조하는 주소를 복사하는 것이 아니라 똑같은 객체를 다른 메모리 주소에 저장한다.
즉, car1에서 속성을 변경해도 car3는 다른 주소를 참조하고 있기 때문에 영향을 받지 않는다.
# 깊은 복사
import copy
car3 = car1.copy()
car3 = copy.deepcopy(car1) # deepcopy()는 배열의 내부 객체까지 복사. 이중 배열이상에서도 완전한 깊은 복사 가능
📍 클래스 상속
클래스는 다른 클래스를 상속하여 상위 클래스의 속성과 기능을 사용할 수 있다.
class CalculatorSuper:
def __init__(self, pNum1, pNum2):
self.pNum1 = pNum1
self.pNum2 = pNum2
def add(self, n1, n2):
return n1 + n2
def sub(self, n1, n2):
return n1 - n2
class CalculatorChild(CalculatorSuper): # 위의 상위 클래스를 상속받는다.
def __init__(self, cNum1, cNum2):
super().__init__(100, 200) # super().__init__ 을 하면 하위 클래스 객체 생성시 상위클래스의 속성 초기화 가능
def mul(self, n1, n2):
return n1 * n2
def div(self, n1, n2):
return n1 / n2
cal = CalculatorChild() # 하위 클래스 객체 생성
cal.add(10, 20) # 상위 클래스의 기능임에도 상속받았기에 사용가능
📍 오버라이딩
오버라이딩 : 하위 클래스에서 상위 클래스의 메서드를 재정의
class Robot:
def fire(self):
print("총알 발사!!")
class NewRobot(Robot): # 상속
def fire(self):
print("레이저 발사!!") # 상위 클래스의 fire 메서드가 아닌 재정의 된 fire로, "레이저 발사!!" 출력
📍 추상클래스
상위 클래스에서 하위 클래스에 메서드 구현을 강요한다.
즉, 상위 클래스에서는 메서드를 선언만 해놓고, 하위 클래스에서 꼭 구현하여야만 기능할 수 있도록 한다.
from abc import ABCMeta
from abc import abstractmethod
class AirPlane(metaclass=ABCMeta):
@abstractmethod
def flight(self): # 추상 클래스를 선언했으므로 하위클래스에서 이 추상 메서드를 꼭 구현하여야만 한다.
pass
class Airliner(AirPlane):
def flight(self): # 추상 메서드 구현
print("시속 400km/h 비행!!")
인수의 개수를 특정하지 않을 때에는 addCal(*num) 과 같이 적으면 정해지지 않은 개수의 인수를 입력 가능
# x, y 를 입력하면 x + y를 반환하는 함수
def addCal(x, y):
return x + y
📍 함수 내에서 다른 함수 호출하기
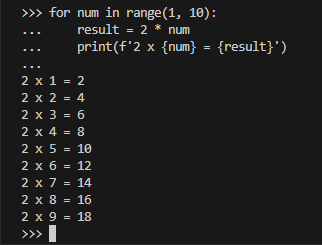
구구단 2단 함수를 호출하면 3단도 이어서 호출하는 구조 작성하기
def guguDan2():
for i in range(1, 10):
print('2 * {} = {}'.format(i, 2*i))
guguDan3() # 함수 안에서 다른 함수 호출
def guguDan3():
for i in range(1, 10):
print('3 * {} = {}'.format(i, 3*i))
guguDan2() # 만든 함수를 호출하면 guguDan3도 함께 호출
📍 함수 만들기 실습
사용자가 길이(cm)를 입력하면 mm로 환산한 값을 반환하는 함수
def cmToMm(cm):
result = cm * 10
return result
length = float(input('길이(cm) 입력: '))
returnValue = cmToMm(length)
print(f'mm 반환값은 {returnValue}mm 입니다.')
📍 전역변수와 지역변수
전역변수 : 함수 밖에 선언된 변수, 함수안에서 재정의 하더라도 시스템에서는 수정되지 않는다.
# num이 10 보다 크면 if 이하 실행, 작거나 같으면 else 이하 실행
num = 6
if num > 10:
print('정답입니다.')
else:
print('오답입니다.')
# 점수에 따라 등급 매기기
score = 77
if score > 90:
print('A')
elif score > 80: # elif -> else if -> 그렇지 않고 이렇다면~ 실행
print('B')
elif score > 70: # 여기에서 True 이므로 C 출력
print('C')
else:
print('D')
📍 조건식
조건을 바탕으로 식 만들기 (ex. 조건에 따라 변수에 값을 다르게 할당)
# 한국이면 블레이크를, 아니라면 Blake를 name에 할당
country = '미국'
name = '블레이크' if country == '한국' else 'Blake'
# name = 'Blake' 할당
📍 중첩 조건문
조건문 안에 또 다른 조건문이 있는 구조
score = 68
if score <= 70:
print('재시험')
# 그렇지 않은 경우, 다시 조건에 따라 나눈다
else:
if score > 90:
print('A')
elif score > 80:
print('B')
elif score > 70:
print('C')
📍 반복문
반복문의 종류
횟수에 의한 반복 : 횟수를 정하고 그만큼 반복 실행
for i in range(10):
print(i)
# 1, 2, 3, 4, 5, 6, 7, 8, 9 반복 출력
조건에 의한 반복 : 조건을 정하고 조건이 만족하는 한 계속 반복 실행
num = 0
while (num < 10):
print(num)
num += 1
# 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 까지 출력 반복 실행하고, 그다음 10이 넘어가므로 종료
기계 학습을 공부하는 20대 학생이라면 이 흥미진진한 분야를 어떻게 시작해야 할지 궁금할 것입니다. 기계 학습은 컴퓨터가 데이터로부터 학습하고 해당 학습을 기반으로 예측 또는 결정을 내리도록 훈련하는 연구 분야로 빠르게 성장하고 있습니다. 다음은 기계 학습을 시작하는 데 도움이 되는 단계별 가이드입니다.
1단계: 기본 사항 배우기
머신 러닝의 기술적 세부 사항을 살펴보기 전에 프로그래밍 및 컴퓨터 과학의 기본 사항을 이해하는 것이 중요합니다. 데이터 구조, 알고리즘 및 Python 또는 R과 같은 프로그래밍 언어와 같은 주제에 대한 탄탄한 기초가 필요합니다. 이러한 기본 사항을 배우기 위해 온라인 과정을 수강하거나 워크숍에 참석할 수 있습니다.
2단계: 기계 학습 프레임워크 선택
컴퓨터 과학에 대한 기초가 탄탄해지면 기계 학습 프레임워크를 선택할 때입니다. 일부 인기 있는 프레임워크에는 TensorFlow, PyTorch 및 Scikit-learn이 포함됩니다. 각 프레임워크에는 고유한 강점과 약점이 있으므로 프로젝트에 적합한 프레임워크를 찾으려면 몇 가지 조사를 수행해야 합니다.
3단계: 데이터 수집 및 정리
기계 학습은 예측이나 결정을 내리기 위해 데이터에 의존합니다. 모델 교육을 시작하려면 먼저 데이터를 수집하고 정리해야 합니다. 여기에는 관련 데이터 소스를 식별하고 데이터를 정리하여 오류와 불일치를 제거하고 기계 학습 프레임워크에서 사용할 데이터를 준비하는 작업이 포함됩니다.
4단계: 기계 학습 알고리즘 선택
선형 회귀, 로지스틱 회귀, 의사 결정 트리 및 신경망을 포함하여 선택할 수 있는 다양한 기계 학습 알고리즘이 있습니다. 각 알고리즘에는 고유한 강점과 약점이 있으므로 프로젝트에 가장 적합한 알고리즘을 선택해야 합니다.
5단계: 모델 교육
기계 학습 프레임워크를 선택하고 데이터를 수집 및 정리하고 알고리즘을 선택했으면 이제 모델을 교육할 차례입니다. 여기에는 머신 러닝 프레임워크에 데이터를 공급하고 알고리즘의 매개변수를 조정하여 모델의 성능을 최적화하는 작업이 포함됩니다.
6단계: 모델 테스트 및 평가
모델을 교육한 후에는 성능을 테스트하고 평가해야 합니다. 여기에는 새 데이터를 모델에 입력하고 예측 또는 결정을 실제 결과와 비교하는 작업이 포함됩니다. 정확도, 정밀도 및 재현율과 같은 메트릭을 사용하여 모델의 성능을 평가할 수 있습니다.
7단계: 모델 구체화 및 개선
테스트 및 평가 결과에 따라 모델을 구체화하고 개선해야 할 수 있습니다. 여기에는 알고리즘의 매개변수 조정, 더 많은 데이터 수집 또는 다른 알고리즘 선택이 포함될 수 있습니다. 목표는 정확한 예측이나 결정을 내릴 수 있도록 모델의 성능을 최적화하는 것입니다.
결론
머신 러닝을 시작하는 것이 어려워 보일 수 있지만 다음 단계를 따르면 고유한 머신 러닝 모델 구축을 시작할 수 있습니다. 계속 배우고 실험하는 것을 잊지 말고 필요할 때 도움을 요청하는 것을 두려워하지 마십시오. 시간과 연습을 통해 숙련된 기계 학습 실무자가 될 수 있습니다.
이 글은 파이토치로 배우는 자연어처리(O'REILLY, 한빛미디어)를 공부한 내용을 바탕으로 작성하였습니다.
퍼셉트론 분류기
완전연결(FC1) 계층 하나를 가진 퍼셉트론 분류기
손실 계산에서 BCEWithLogitsLoss()를 사용하도록 sigmoid를 거치지 않은 채 출력
class ReviewClassifier(nn.Module):
""" 간단한 퍼셉트론 기반 분류기 """
def __init__(self, num_features):
"""
매개변수:
num_features (int): 입력 특성 벡터의 크기
"""
super(ReviewClassifier, self).__init__()
self.fc1 = nn.Linear(in_features=num_features,
out_features=1)
def forward(self, x_in, apply_sigmoid=False):
""" 분류기의 정방향 계산
매개변수:
x_in (torch.Tensor): 입력 데이터 텐서
x_in.shape는 (batch, num_features)입니다.
apply_sigmoid (bool): 시그모이드 활성화 함수를 위한 플래그
크로스-엔트로피 손실을 사용하려면 False로 지정합니다
반환값:
결과 텐서. tensor.shape은 (batch,)입니다.
"""
y_out = self.fc1(x_in).squeeze()
if apply_sigmoid:
y_out = torch.sigmoid(y_out)
return y_out
하이퍼파라미터와 프로그램 옵션 변수 설정
argparse의 Namespace를 사용하여 결정 요소를 관리
args = Namespace(
# 날짜와 경로 정보
frequency_cutoff=25,
model_state_file='model.pth',
review_csv='data/reviews_with_splits_lite.csv',
# review_csv='data/yelp/reviews_with_splits_full.csv',
save_dir='model_storage/ch3/yelp/',
vectorizer_file='vectorizer.json',
# 모델 하이퍼파라미터 없음
# 훈련 하이퍼파라미터
batch_size=128,
early_stopping_criteria=5,
learning_rate=0.001,
num_epochs=100,
seed=1337,
# 실행 옵션
catch_keyboard_interrupt=True,
cuda=True,
expand_filepaths_to_save_dir=True,
reload_from_files=False,
)
훈련 준비
훈련하는 동안 생성될 중요 정보(loss, accuracy)를 저장할 딕셔너리를 생성하고,
미리 만들어 둔 클래스를 호출해 dataset, vectorizer, classifier를 준비
nn.BCEWithLogitsLoss() 를 손실함수로 설정
optimizer를 Adam으로 설정
compute_accuracy() : 출력 결과와 정답을 비교해 정확도 체크하는 함수
def make_train_state(args):
return {'stop_early': False,
'early_stopping_step': 0,
'early_stopping_best_val': 1e8,
'learning_rate': args.learning_rate,
'epoch_index': 0,
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': [],
'test_loss': -1,
'test_acc': -1,
'model_filename': args.model_state_file}
def update_train_state(args, model, train_state):
""" 훈련 상태를 업데이트합니다.
Components:
- 조기 종료: 과대 적합 방지
- 모델 체크포인트: 더 나은 모델을 저장합니다
:param args: 메인 매개변수
:param model: 훈련할 모델
:param train_state: 훈련 상태를 담은 딕셔너리
:returns:
새로운 훈련 상태
"""
# 적어도 한 번 모델을 저장합니다
if train_state['epoch_index'] == 0:
torch.save(model.state_dict(), train_state['model_filename'])
train_state['stop_early'] = False
# 성능이 향상되면 모델을 저장합니다
elif train_state['epoch_index'] >= 1:
loss_tm1, loss_t = train_state['val_loss'][-2:]
# 손실이 나빠지면
if loss_t >= train_state['early_stopping_best_val']:
# 조기 종료 단계 업데이트
train_state['early_stopping_step'] += 1
# 손실이 감소하면
else:
# 최상의 모델 저장
if loss_t < train_state['early_stopping_best_val']:
torch.save(model.state_dict(), train_state['model_filename'])
# 조기 종료 단계 재설정
train_state['early_stopping_step'] = 0
# 조기 종료 여부 확인
train_state['stop_early'] = \
train_state['early_stopping_step'] >= args.early_stopping_criteria
return train_state
def compute_accuracy(y_pred, y_target):
y_target = y_target.cpu()
y_pred_indices = (torch.sigmoid(y_pred)>0.5).cpu().long()#.max(dim=1)[1]
n_correct = torch.eq(y_pred_indices, y_target).sum().item()
return n_correct / len(y_pred_indices) * 100
if args.reload_from_files:
# 체크포인트에서 훈련을 다시 시작
print("데이터셋과 Vectorizer를 로드합니다")
dataset = ReviewDataset.load_dataset_and_load_vectorizer(args.review_csv,
args.vectorizer_file)
else:
print("데이터셋을 로드하고 Vectorizer를 만듭니다")
#데이터셋과 Vectorizer 만들기
dataset = ReviewDataset.load_dataset_and_make_vectorizer(args.review_csv)
dataset.save_vectorizer(args.vectorizer_file)
vectorizer = dataset.get_vectorizer()
classifier = ReviewClassifier(num_features=len(vectorizer.review_vocab))
classifier = classifier.to(args.device)
loss_func = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(classifier.parameters(), lr=args.learning_rate)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
mode='min', factor=0.5,
patience=1)
train_state = make_train_state(args)
이 글은 파이토치로 배우는 자연어처리(O'REILLY, 한빛미디어)를 공부한 내용을 바탕으로 작성하였습니다.
yelp 레스토랑 리뷰 데이터셋
리뷰 텍스트(review)와 그에 맞는 평가 레이블(rating)를 준비하고, train, valid, test (0.7, 0.15, 0.15)로 분류
from argparse import Namespace
from collections import Counter
import json
import os
import re
import string
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import tqdm
Dataset
review dataset 로드하고, ReviewVectorizer 객체 생성
class ReviewDataset(Dataset):
def __init__(self, review_df, vectorizer):
"""
매개변수:
review_df (pandas.DataFrame): 데이터셋
vectorizer (ReviewVectorizer): ReviewVectorizer 객체
"""
self.review_df = review_df
self._vectorizer = vectorizer
self.train_df = self.review_df[self.review_df.split=='train']
self.train_size = len(self.train_df)
self.val_df = self.review_df[self.review_df.split=='val']
self.validation_size = len(self.val_df)
self.test_df = self.review_df[self.review_df.split=='test']
self.test_size = len(self.test_df)
self._lookup_dict = {'train': (self.train_df, self.train_size),
'val': (self.val_df, self.validation_size),
'test': (self.test_df, self.test_size)}
self.set_split('train')
@classmethod
def load_dataset_and_make_vectorizer(cls, review_csv):
""" 데이터셋을 로드하고 새로운 ReviewVectorizer 객체를 만듭니다
매개변수:
review_csv (str): 데이터셋의 위치
반환값:
ReviewDataset의 인스턴스
"""
review_df = pd.read_csv(review_csv)
train_review_df = review_df[review_df.split=='train']
return cls(review_df, ReviewVectorizer.from_dataframe(train_review_df))
@classmethod
def load_dataset_and_load_vectorizer(cls, review_csv, vectorizer_filepath):
""" 데이터셋을 로드하고 새로운 ReviewVectorizer 객체를 만듭니다.
캐시된 ReviewVectorizer 객체를 재사용할 때 사용합니다.
매개변수:
review_csv (str): 데이터셋의 위치
vectorizer_filepath (str): ReviewVectorizer 객체의 저장 위치
반환값:
ReviewDataset의 인스턴스
"""
review_df = pd.read_csv(review_csv)
vectorizer = cls.load_vectorizer_only(vectorizer_filepath)
return cls(review_df, vectorizer)
@staticmethod
def load_vectorizer_only(vectorizer_filepath):
""" 파일에서 ReviewVectorizer 객체를 로드하는 정적 메서드
매개변수:
vectorizer_filepath (str): 직렬화된 ReviewVectorizer 객체의 위치
반환값:
ReviewVectorizer의 인스턴스
"""
with open(vectorizer_filepath) as fp:
return ReviewVectorizer.from_serializable(json.load(fp))
def save_vectorizer(self, vectorizer_filepath):
""" ReviewVectorizer 객체를 json 형태로 디스크에 저장합니다
매개변수:
vectorizer_filepath (str): ReviewVectorizer 객체의 저장 위치
"""
with open(vectorizer_filepath, "w") as fp:
json.dump(self._vectorizer.to_serializable(), fp)
def get_vectorizer(self):
""" 벡터 변환 객체를 반환합니다 """
return self._vectorizer
def set_split(self, split="train"):
""" 데이터프레임에 있는 열을 사용해 분할 세트를 선택합니다
매개변수:
split (str): "train", "val", "test" 중 하나
"""
self._target_split = split
self._target_df, self._target_size = self._lookup_dict[split]
def __len__(self):
return self._target_size
def __getitem__(self, index):
""" 파이토치 데이터셋의 주요 진입 메서드
매개변수:
index (int): 데이터 포인트의 인덱스
반환값:
데이터 포인트의 특성(x_data)과 레이블(y_target)로 이루어진 딕셔너리
"""
row = self._target_df.iloc[index]
review_vector = \
self._vectorizer.vectorize(row.review)
rating_index = \
self._vectorizer.rating_vocab.lookup_token(row.rating)
return {'x_data': review_vector,
'y_target': rating_index}
def get_num_batches(self, batch_size):
""" 배치 크기가 주어지면 데이터셋으로 만들 수 있는 배치 개수를 반환합니다
매개변수:
batch_size (int)
반환값:
배치 개수
"""
return len(self) // batch_size
Vocabulary
토큰을 정수로 매핑하는 단계
token_to_idx 과 idx_to_token 두 가지 딕셔너리 반환
add_token() : 새로운 토큰 추가하기
lookup_token() : 특정 토큰에 해당하는 인덱스 추출
lookup_index() : 특정 인덱스에 해당하는 토큰 추출
class Vocabulary(object):
""" 매핑을 위해 텍스트를 처리하고 어휘 사전을 만드는 클래스 """
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
매개변수:
token_to_idx (dict): 기존 토큰-인덱스 매핑 딕셔너리
add_unk (bool): UNK 토큰을 추가할지 지정하는 플래그
unk_token (str): Vocabulary에 추가할 UNK 토큰
"""
if token_to_idx is None:
token_to_idx = {}
self._token_to_idx = token_to_idx
self._idx_to_token = {idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
""" 직렬화할 수 있는 딕셔너리를 반환합니다 """
return {'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
""" 직렬화된 딕셔너리에서 Vocabulary 객체를 만듭니다 """
return cls(**contents)
def add_token(self, token):
""" 토큰을 기반으로 매핑 딕셔너리를 업데이트합니다
매개변수:
token (str): Vocabulary에 추가할 토큰
반환값:
index (int): 토큰에 상응하는 정수
"""
if token in self._token_to_idx:
index = self._token_to_idx[token]
else:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
""" 토큰 리스트를 Vocabulary에 추가합니다.
매개변수:
tokens (list): 문자열 토큰 리스트
반환값:
indices (list): 토큰 리스트에 상응되는 인덱스 리스트
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
""" 토큰에 대응하는 인덱스를 추출합니다.
토큰이 없으면 UNK 인덱스를 반환합니다.
매개변수:
token (str): 찾을 토큰
반환값:
index (int): 토큰에 해당하는 인덱스
노트:
UNK 토큰을 사용하려면 (Vocabulary에 추가하기 위해)
`unk_index`가 0보다 커야 합니다.
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
""" 인덱스에 해당하는 토큰을 반환합니다.
매개변수:
index (int): 찾을 인덱스
반환값:
token (str): 인텍스에 해당하는 토큰
에러:
KeyError: 인덱스가 Vocabulary에 없을 때 발생합니다.
"""
if index not in self._idx_to_token:
raise KeyError("Vocabulary에 인덱스(%d)가 없습니다." % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
Vectorizer
vocabulary에서 토큰-정수 매핑한 정보를 바탕으로 정수 인덱스를 1로 하는 원-핫 벡터 생성
메모리가 낭비되므로, 25번 이상 등장한 단어로 제한
class ReviewVectorizer(object):
""" 어휘 사전을 생성하고 관리합니다 """
def __init__(self, review_vocab, rating_vocab):
"""
매개변수:
review_vocab (Vocabulary): 단어를 정수에 매핑하는 Vocabulary
rating_vocab (Vocabulary): 클래스 레이블을 정수에 매핑하는 Vocabulary
"""
self.review_vocab = review_vocab
self.rating_vocab = rating_vocab
def vectorize(self, review):
""" 리뷰에 대한 원-핫 벡터를 만듭니다
매개변수:
review (str): 리뷰
반환값:
one_hot (np.ndarray): 원-핫 벡터
"""
one_hot = np.zeros(len(self.review_vocab), dtype=np.float32)
for token in review.split(" "):
if token not in string.punctuation:
one_hot[self.review_vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, review_df, cutoff=25):
""" 데이터셋 데이터프레임에서 Vectorizer 객체를 만듭니다
매개변수:
review_df (pandas.DataFrame): 리뷰 데이터셋
cutoff (int): 빈도 기반 필터링 설정값
반환값:
ReviewVectorizer 객체
"""
review_vocab = Vocabulary(add_unk=True)
rating_vocab = Vocabulary(add_unk=False)
# 점수를 추가합니다
for rating in sorted(set(review_df.rating)):
rating_vocab.add_token(rating)
# count > cutoff인 단어를 추가합니다
word_counts = Counter()
for review in review_df.review:
for word in review.split(" "):
if word not in string.punctuation:
word_counts[word] += 1
for word, count in word_counts.items():
if count > cutoff:
review_vocab.add_token(word)
return cls(review_vocab, rating_vocab)
@classmethod
def from_serializable(cls, contents):
""" 직렬화된 딕셔너리에서 ReviewVectorizer 객체를 만듭니다
매개변수:
contents (dict): 직렬화된 딕셔너리
반환값:
ReviewVectorizer 클래스 객체
"""
review_vocab = Vocabulary.from_serializable(contents['review_vocab'])
rating_vocab = Vocabulary.from_serializable(contents['rating_vocab'])
return cls(review_vocab=review_vocab, rating_vocab=rating_vocab)
def to_serializable(self):
""" 캐싱을 위해 직렬화된 딕셔너리를 만듭니다
반환값:
contents (dict): 직렬화된 딕셔너리
"""
return {'review_vocab': self.review_vocab.to_serializable(),
'rating_vocab': self.rating_vocab.to_serializable()}
DataLoader
Dataset을 배치 단위로 순회하며 반환
generate_batches() : 현재 이용할 데이터를 지정된 device로 보내는 함수
def generate_batches(dataset, batch_size, shuffle=True,
drop_last=True, device="cpu"):
"""
파이토치 DataLoader를 감싸고 있는 제너레이터 함수.
걱 텐서를 지정된 장치로 이동합니다.
"""
dataloader = DataLoader(dataset=dataset, batch_size=batch_size,
shuffle=shuffle, drop_last=drop_last)
for data_dict in dataloader:
out_data_dict = {}
for name, tensor in data_dict.items():
out_data_dict[name] = data_dict[name].to(device)
yield out_data_dict
이렇게 데이터를 모델에 입력하도록 클래스를 구성했다. 다음 게시물에서 분류기 모델을 만들고, 훈련을 준비해보자.
이 글은 파이토치로 배우는 자연어처리(O'REILLY, 한빛미디어)를 공부한 내용을 바탕으로 작성하였습니다.
1. 퍼셉트론 구현
y = f(wx + b)
x : 입력
w : 가중치
b : 편향, 절편
y : 출력
f(): 활성화 함수
선형 함수 표현인 wx + b 는 아핀 변환(affine transform)이라고 불린다.
class Perceptron(nn.Module):
""" 퍼셉트론은 하나의 선형 층입니다 """
def __init__(self, input_dim):
"""
매개변수:
input_dim (int): 입력 특성의 크기
"""
super(Perceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, 1)
def forward(self, x_in):
"""퍼셉트론의 정방향 계산
매개변수:
x_in (torch.Tensor): 입력 데이터 텐서
x_in.shape는 (batch, num_features)입니다.
반환값:
결과 텐서. tensor.shape는 (batch,)입니다.
"""
return torch.sigmoid(self.fc1(x_in))
super() : 하위 클래스에서 부모 클래스의 메소드를 사용할수 있도록 한다.
nn.Linear(): 가중치와 절편에 관련된 작업, 아핀 변환 수행
forward() : 순전파를 수행하고, 활성화 함수를 거친 값을 반환
2. 활성화 함수
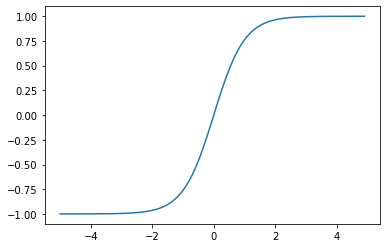
2-1. 시그모이드(sigmoid)
import torch
import matplotlib.pyplot as plt
x = torch.arange(-5., 5., 0.1)
y = torch.sigmoid(x)
plt.plot(x.numpy(), y.detach().numpy())
plt.show()
detach() : 해당 층에서 gradient의 전파를 멈추는 역할
sigmoid 그래프
출력층에서 활용, 0 ~ 1 사이의 값을 반환하기 때문에 출력을 확률로 압축하는데 사용.
2-2. 하이퍼볼릭 탄젠트(tanh)
import torch
import matplotlib.pyplot as plt
x = torch.arange(-5., 5., 0.1)
y = torch.tanh(x)
plt.plot(x.numpy(), y.detach().numpy())
plt.show()
tanh 그래프
출력이 -1 ~ 1 사이의 값을 가져 sigmoid보다 반환값의 변화폭이 크기에 기울기 소실 증상이 적음.
은닉층에서 sigmoid 보다 많이 사용.
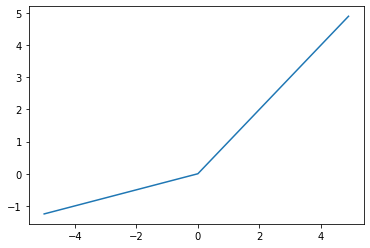
2.3. 렐루(ReLU)
import torch
import matplotlib.pyplot as plt
relu = torch.nn.ReLU()
x = torch.arange(-5., 5., 0.1)
y = relu(x)
plt.plot(x.numpy(), y.detach().numpy())
plt.show()
ReLU 그래프
음수를 제거하고 양수에서는 입력값을 그대로 출력하여 그래디언트 소실문제를 막음.
특정 출력이 0이되면 돌아오지 않고 소멸되는 '죽은 렐루' 현상 생김.
2.4 PReLU
import torch.nn as nn
import matplotlib.pyplot as plt
prelu = nn.PReLU(num_parameters=1)
x = torch.arange(-5., 5., 0.1)
y = prelu(x)
plt.plot(x.numpy(), y.detach().numpy())
plt.show()